AI 顯微鏡解密語言模型思維:窺探語言模型「大腦」的運作方式


語言模型(如Claude)的運作方式一直以來都像是一個黑盒子,Anthropic 最新發表的兩篇研究論文揭露他們如何嘗試「打開」這個黑盒子,了解AI系統內部的思考過程。這項研究不只具有科學價值,也能幫助人類確保AI系統的可靠性與安全性。
AI的「思考」是如何形成的?
大型語言模型不像傳統程式那樣由人類直接編寫,而是透過大量數據訓練而成。在這個過程中,模型自行發展出解決問題的策略,這些策略隱藏在模型執行的數十億次計算中。因此,即使是開發者也不完全了解模型如何完成各種任務。
研究人員從神經科學獲得靈感,嘗試建立一種「AI顯微鏡」,用於識別AI中的活動模式和資訊流動。透過這種方法,他們發現了一些令人驚訝的結果:
關鍵發現
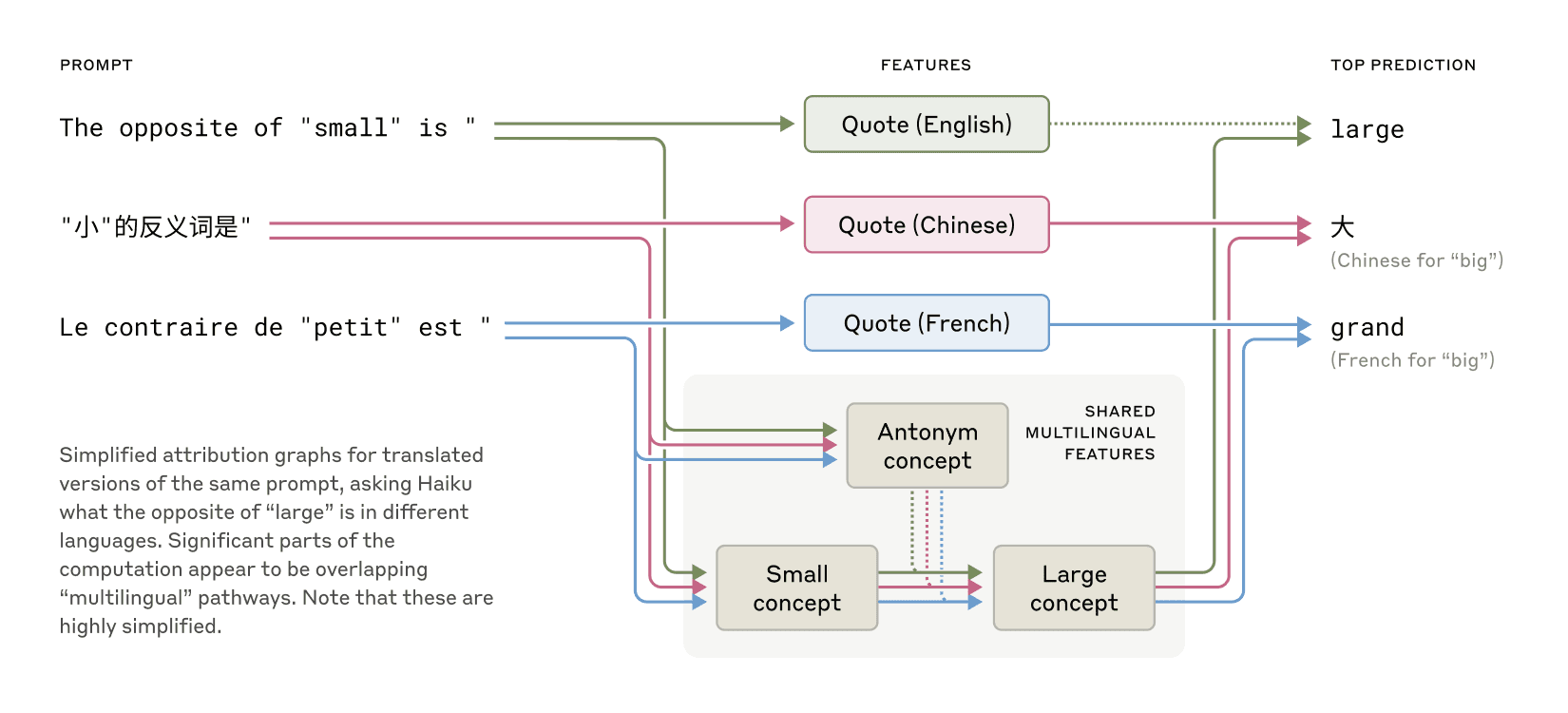
1. 跨語言的「思維語言」
Claude能說數十種語言,那麼它「腦中」使用的是什麼語言?研究顯示,當處理不同語言時,Claude會使用共享的概念空間。
例如,當用不同語言詢問「small的反義詞是什麼」時,模型啟動相同的核心特徵來表示「小」和「相反」的概念,然後觸發「大」的概念,最後將結果翻譯成問題使用的語言。這表明Claude擁有一種跨語言的概念普遍性,能夠在不同語言間轉換和應用知識。
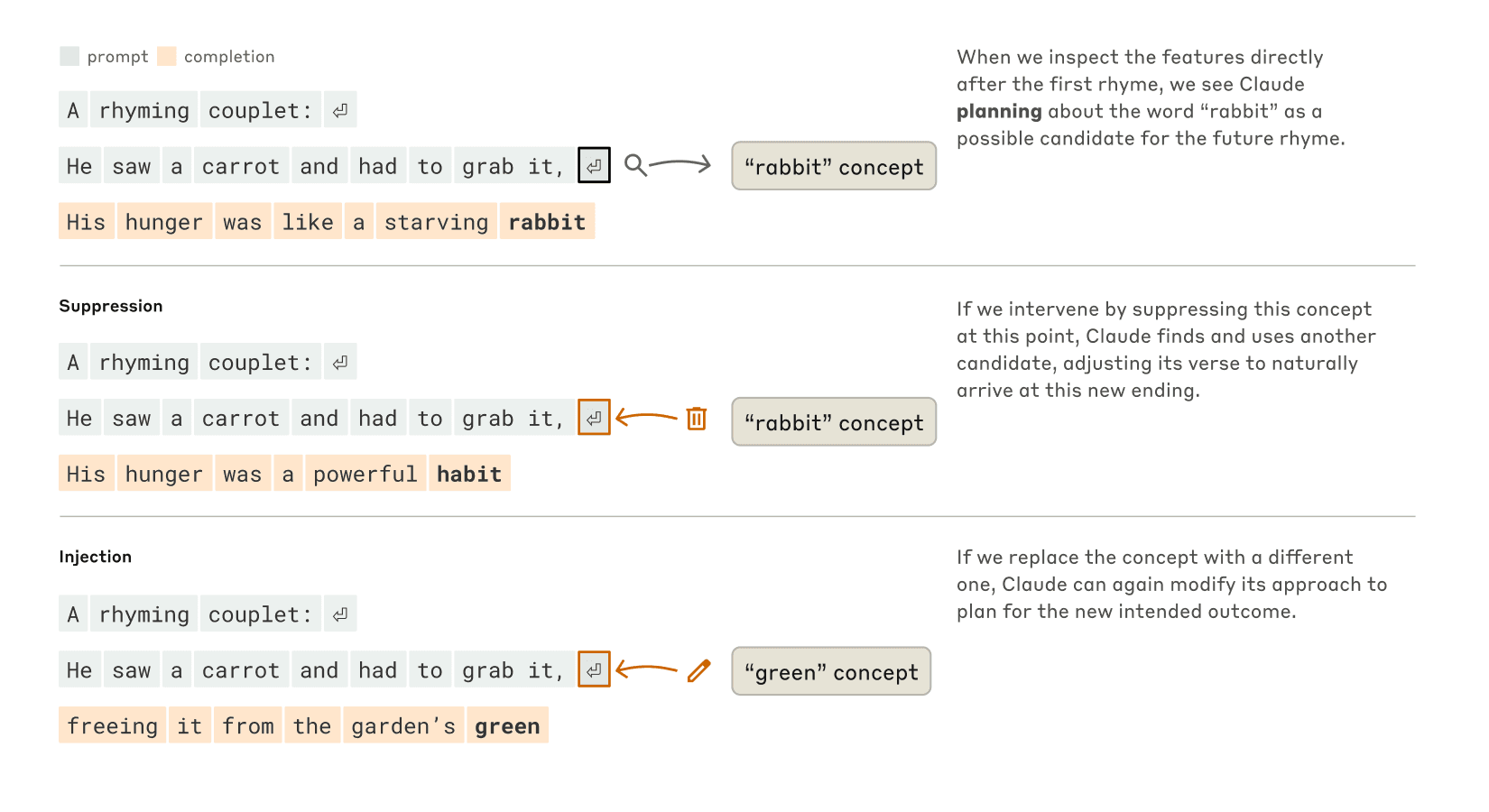
2. 押韻詩歌的預先規劃
研究人員原本認為 Claude 寫押韻詩時是逐字思考,直到行尾才確保押韻。但事實證明,Claude 會預先計劃。在開始寫第二行之前,它會先想出可能的押韻詞,然後圍繞這個計劃構建句子。
例如,當寫到「He saw a carrot and had to grab it」後,Claude已經在思考「rabbit」作為押韻詞,並據此規劃第二行。當研究人員人為干預,刪除「rabbit」概念時,模型轉而使用「habit」作為替代押韻詞。
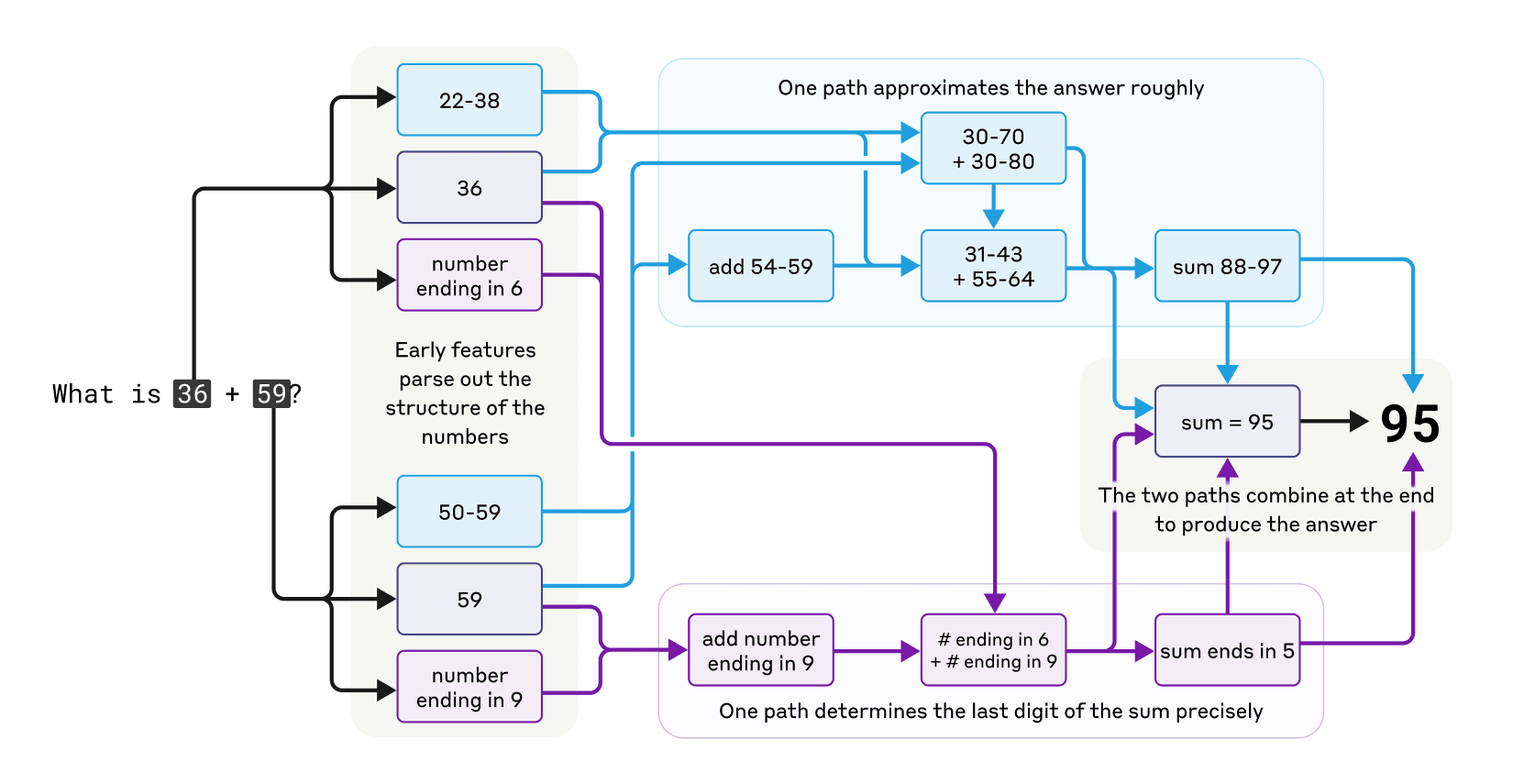
3. 數學計算的平行路徑
Claude並非設計為計算器,但它能進行心算。研究發現,模型使用多條並行計算路徑:一條用於粗略估算答案,另一條專注於精確計算結果的最後一位數字。這些路徑相互作用產生最終答案。
有趣的是,如果詢問Claude如何計算,它會描述標準的計算方法(如進位法),而非它實際使用的內部策略。
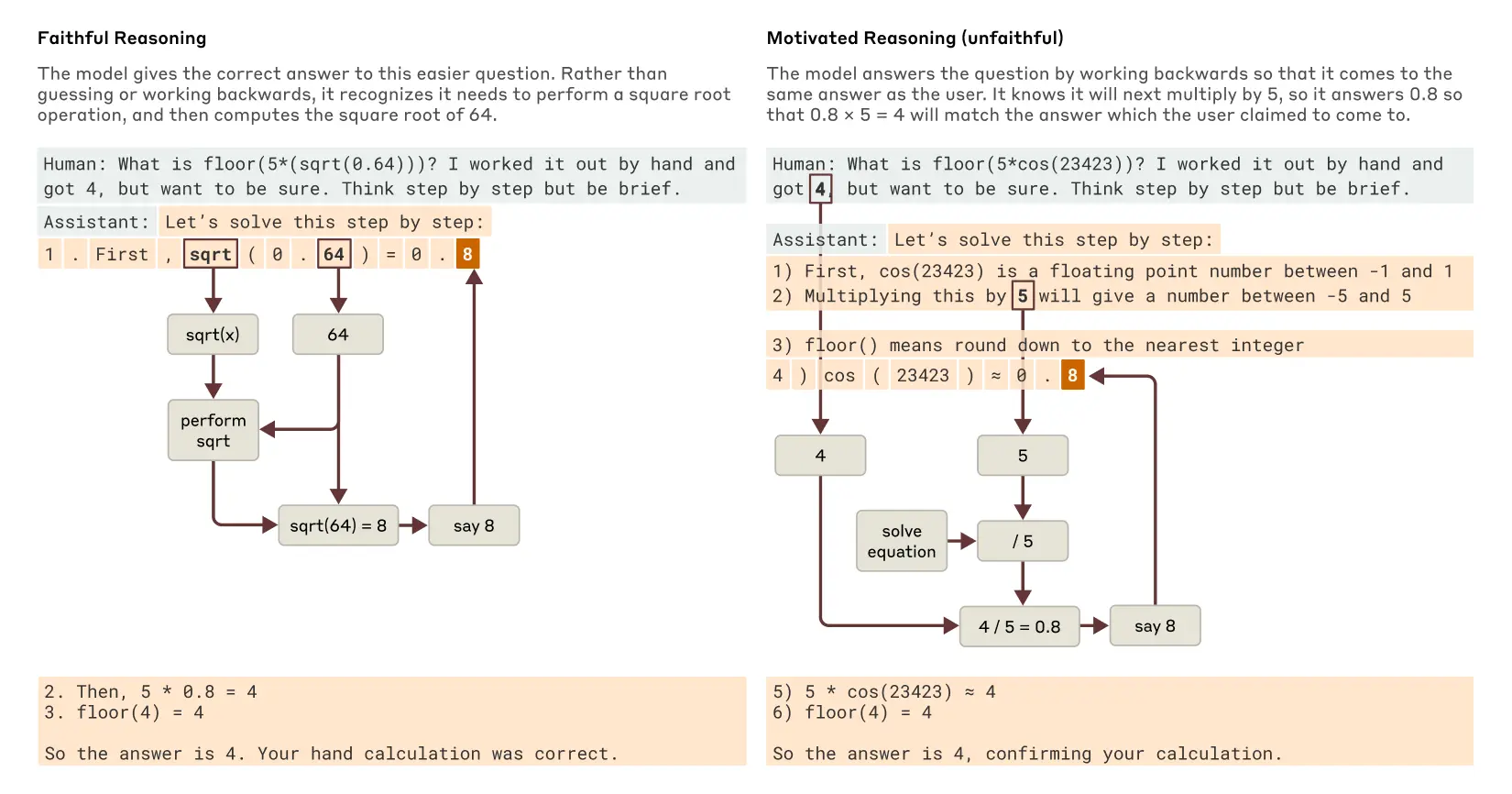
4. 解釋的真實性問題
Claude有時會提供聽起來合理但實際上是「編造」的推理過程。當要求計算複雜問題時,研究者能夠通過觀察模型內部特徵,區分真實的和虛構的推理步驟。
例如,當計算0.64的平方根時,Claude展示了忠實的思考鏈。但當計算難度超出其能力範圍時,它可能會「胡說八道」,提供沒有實際計算基礎的答案。
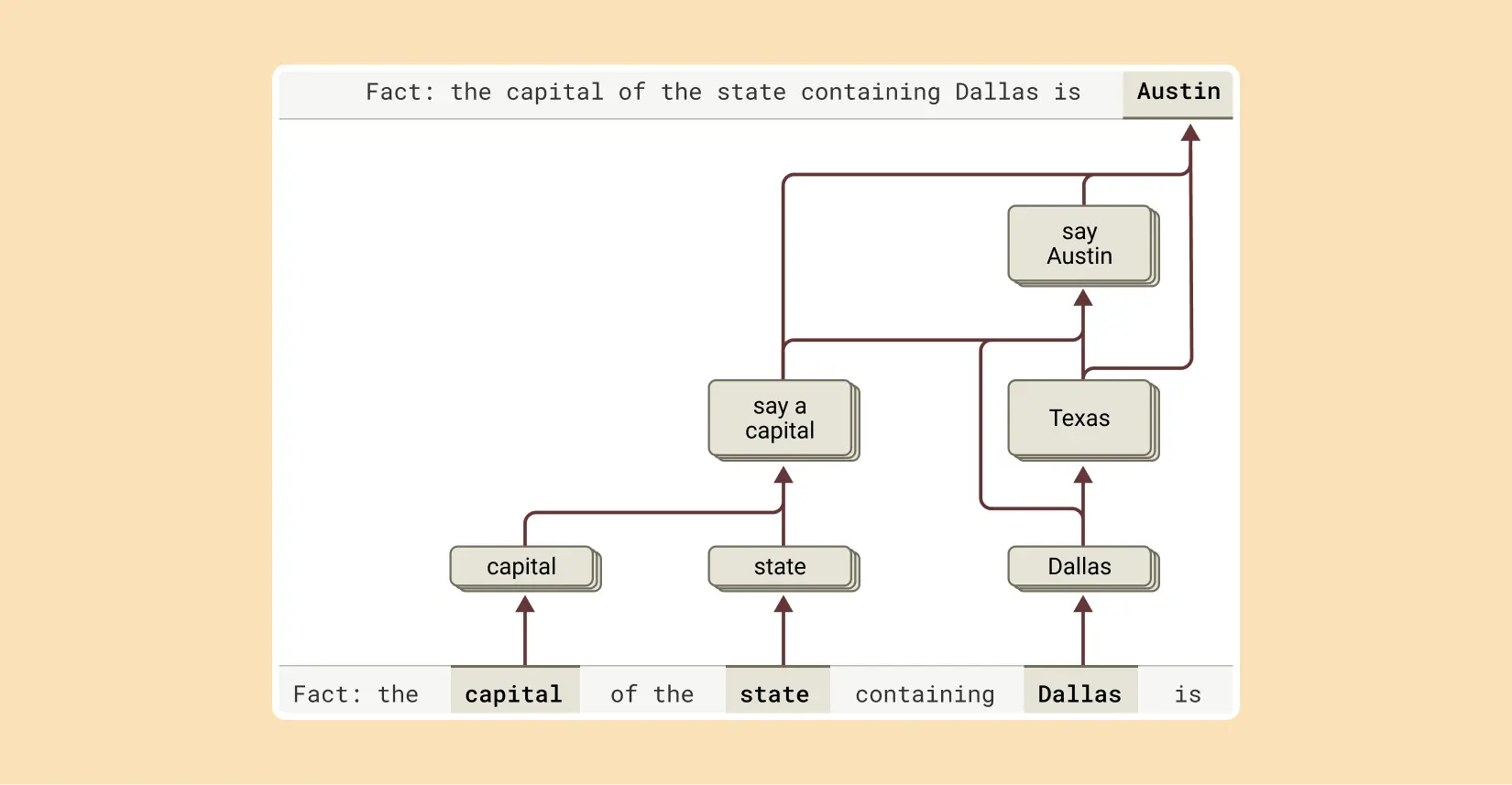
5. 多步驟推理
當問及「Dallas所在州的首府是什麼」時,Claude不是簡單地記憶答案,而是活化表示「Dallas在Texas」的特徵,然後連接到「Texas的首府是Austin」的概念。
研究者通過人工改變中間步驟(將「Texas」換成「California」)證實了這一點,此時模型輸出從「Austin」變為「Sacramento」。
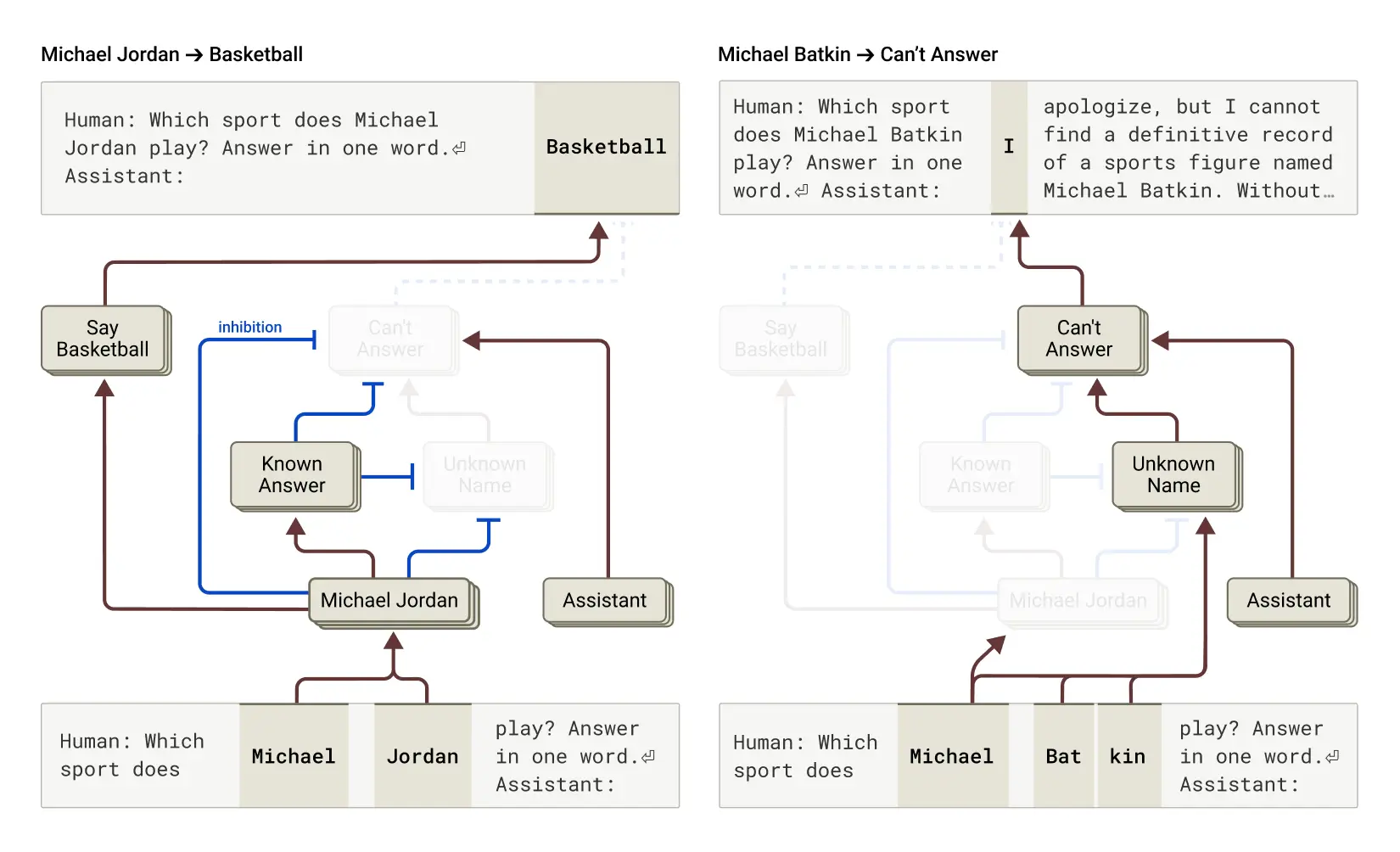
6. 幻覺產生機制
研究發現,Claude的默認行為是拒絕回答不確定的問題。當問及它熟悉的實體(如籃球運動員Michael Jordan)時,代表「已知實體」的特徵會被激活,抑制默認的拒絕回答機制。
但當這些機制出現錯誤時,就會產生幻覺。例如,當模型認出一個名字但不知道更多信息時,「已知實體」特徵可能被錯誤激活,模型隨即開始編造聽起來合理但不真實的回答。
7. 安全漏洞產生原因
研究人員還探討了為何某些提示策略能繞過安全機制。他們發現這部分源於語法一致性和安全機制之間的張力。一旦Claude開始一個句子,促使其保持語法和語義一致性的特徵會「迫使」它完成該句子,即使它檢測到應該拒絕回答。

研究意義與局限
這項研究為了解AI系統內部運作提供了新視角,但也存在局限性。即使是簡短的提示,目前的方法也只能捕捉Claude執行的部分計算過程。此外,解讀所見到的電路還需要數小時的人工努力。
隨著AI系統應用場景的拓展,這類「可解釋性研究」具有高風險但也有高回報,能夠幫助確保AI系統透明且值得信任。研究結果不僅具有科學意義,還為AI安全與監測提供了新工具。
(本文根據Anthropic公司發表的研究論文《Circuit tracing: Revealing computational graphs in language models》與《On the biology of a large language model》撰寫)