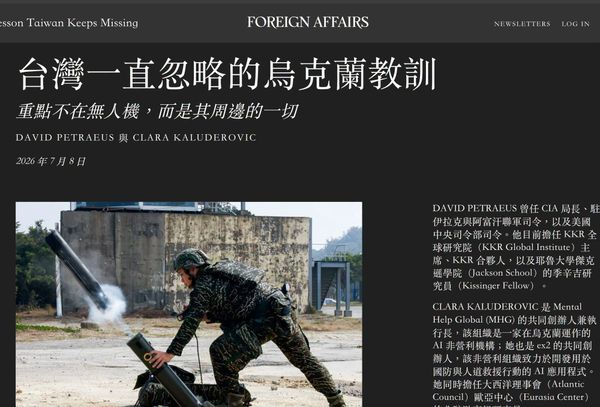
Saronic 的無人船六月救人、七月炸港,四天後宣布蓋 32 億美元造船廠
2026 年 6 月 9 日凌晨,一架 AH-64 阿帕契攻擊直升機墜落在阿曼外海,把兩名飛行員從水裡撈起來的,是一艘 7.3 公尺長、船上沒有人的無人水面載具(USV)。美軍第五艦隊第 59 特遣隊把這艘船開過去,這是美軍第一次公開確認在實戰環境用無人船救回機組員。 一個月又三天之後,7 月 12 日晚間,三艘外型一模一樣的船從波斯灣出發,一路開進伊朗班達阿巴斯(Bandar Abbas)海軍基地,撞上潛艦與艦艇維修設施引爆。美軍中央司令部隔天證實,這是美軍第一次在實戰中使用海上攻擊無人艇。 同一款船,同一條產線,任務決定它今天是救生艇還是彈藥。這款船叫 Corsair,做的公司叫 Saronic Technologies,2022 年才在德州奧斯汀成立。 而就在四天前的 7 月 16 日,這家成立四年的公司宣布要在德州布朗斯維爾(